
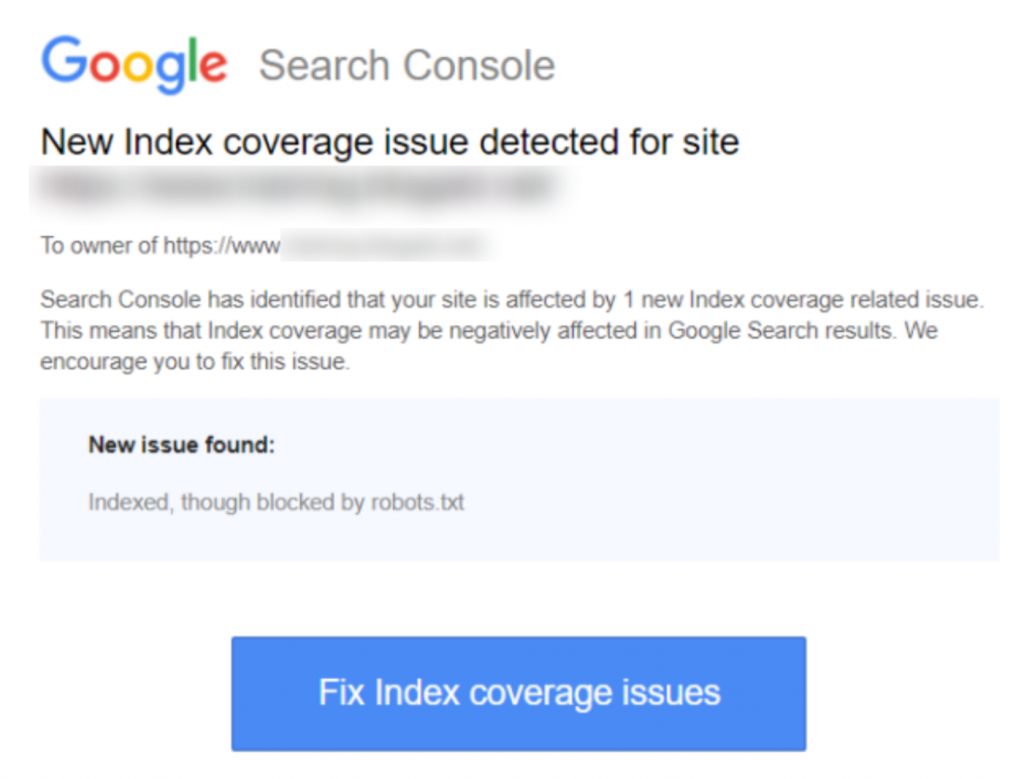
Wenn Sie die Warnung ‘Indexed, though blocked by robots.txt’ in der Google Search Console erhalten haben, sollten Sie diese so schnell wie möglich beheben, da sie die Fähigkeit Ihrer Seiten, überhaupt in den Suchmaschinenergebnisseiten (SERPS) zu ranken, beeinträchtigen könnte.
Eine robots.txt-Datei ist eine Datei, die sich im Verzeichnis Ihrer Website befindet und Suchmaschinen-Crawlern, wie dem Google-Bot, Anweisungen gibt, welche Dateien sie ansehen sollten und welche nicht.
„Indexed, though blocked by robots.txt“ bedeutet, dass Google Ihre Seite gefunden hat, aber auch eine Anweisung gefunden hat, sie in Ihrer robots-Datei zu ignorieren (was bedeutet, dass sie nicht in den Ergebnissen erscheinen wird).
Manchmal ist dies absichtlich, oder es passiert aus Versehen, aus einer Reihe von unten aufgeführten Gründen, und kann behoben werden.
Hier ist ein Screenshot der Benachrichtigung:
Identifizieren Sie die betroffene(n) Seite(n) oder URL(s)
Wenn Sie eine Benachrichtigung von Google Search Console (GSC) erhalten haben, müssen Sie die betreffende(n) Seite(n) oder URL(s) identifizieren.
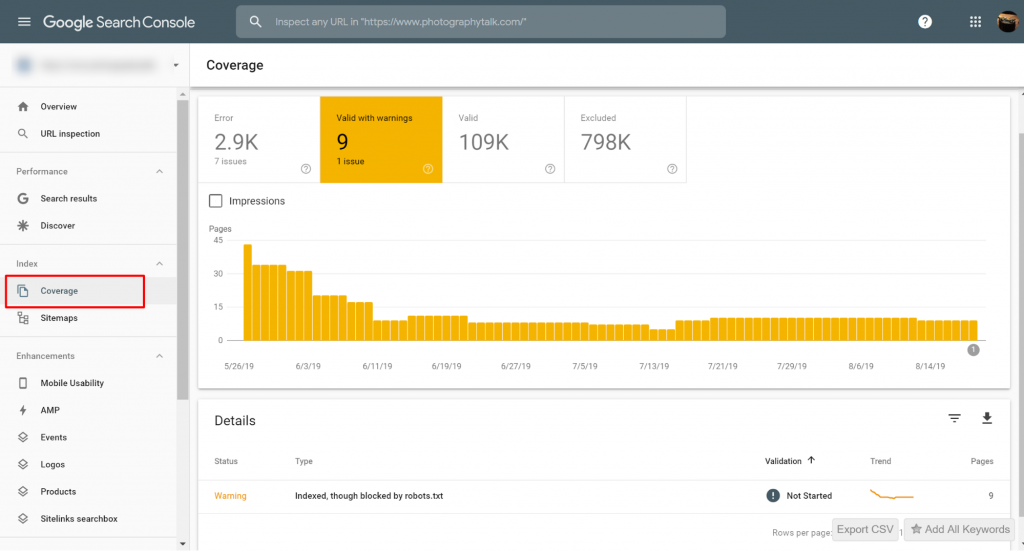
Sie können Seiten mit den Problemen "Indexed, though blocked by robots.txt" in der Google Search Console>>Coverage ansehen. Wenn Sie das Warnetikett nicht sehen, dann sind Sie frei und klar.
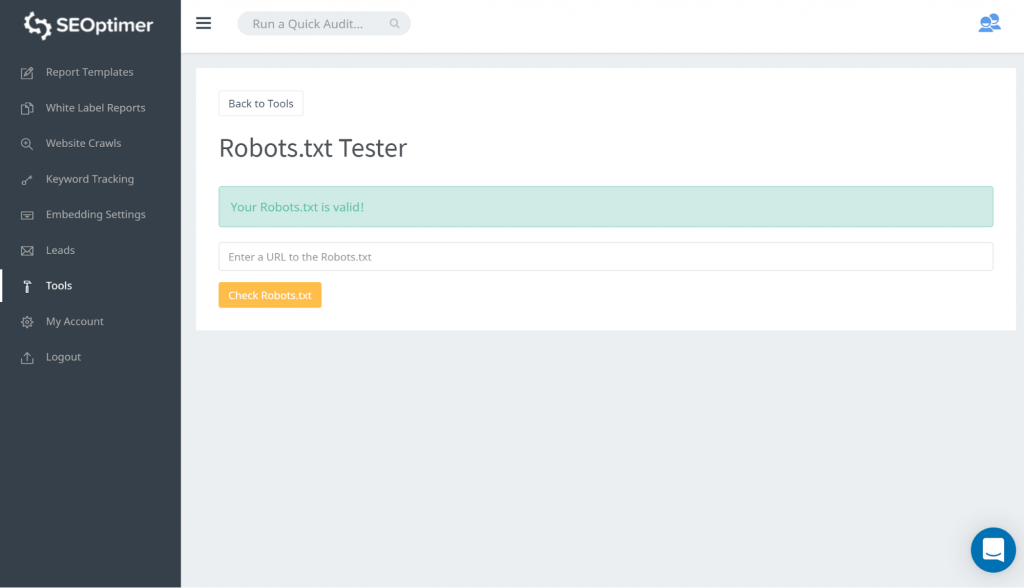
Ein Weg, um Ihre robots.txt zu testen, ist die Verwendung unseres robots.txt Testers. Es kann sein, dass Sie damit einverstanden sind, dass alles, was blockiert wird, auch ‘blockiert’ bleibt. Sie müssen daher keine Maßnahmen ergreifen.
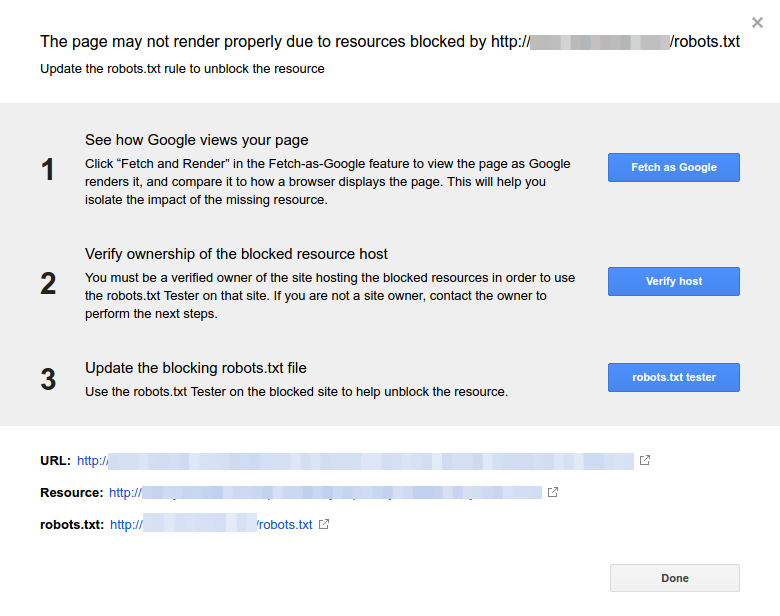
Sie können auch diesem GSC-Link folgen. Dann müssen Sie:
- Öffnen Sie die Liste der blockierten Ressourcen und wählen Sie die Domain aus.
- Klicken Sie auf jede Ressource. Sie sollten dieses Popup sehen:
Ermitteln Sie den Grund für die Benachrichtigung
Die Benachrichtigung kann aus mehreren Gründen resultieren. Hier sind die gängigen:
Aber zuerst, es ist nicht unbedingt ein Problem, wenn Seiten durch robots.txt blockiert werden. Es könnte absichtlich so gestaltet worden sein, aus Gründen wie zum Beispiel, dass der Entwickler unnötige / Kategorie-Seiten oder Duplikate blockieren wollte. Also, was sind die Diskrepanzen?
Falsches URL-Format
Manchmal kann das Problem von einer URL herrühren, die eigentlich keine Seite ist. Zum Beispiel, wenn die URL https://www.seoptimer.com/?s=digital+marketing ist, müssen Sie wissen, auf welche Seite die URL aufgelöst wird.
Wenn es sich um eine Seite mit bedeutendem Inhalt handelt, den Ihre Nutzer wirklich sehen sollen, dann müssen Sie die URL ändern. Dies ist bei Content-Management-Systemen (CMS) wie Wordpress möglich, wo Sie den Slug einer Seite bearbeiten können.
Wenn die Seite nicht wichtig ist oder bei unserem Beispiel /?s=digital+marketing, es sich um eine Suchanfrage aus unserem Blog handelt, dann besteht keine Notwendigkeit, den GSC-Fehler zu beheben.
Es macht keinen Unterschied, ob es indexiert ist oder nicht, da es nicht einmal eine echte URL ist, sondern eine Suchanfrage. Alternativ können Sie die Seite löschen.
Seiten, die indexiert werden sollten
Es gibt mehrere Gründe, warum Seiten, die indexiert werden sollten, nicht indexiert werden. Hier sind einige davon:
- Haben Sie Ihre Robot-Direktiven überprüft? Möglicherweise haben Sie Direktiven in Ihrer robots.txt-Datei eingefügt, die das Indizieren von Seiten verbieten, die eigentlich indiziert werden sollten, zum Beispiel Tags und Kategorien. Tags und Kategorien sind tatsächliche URLs auf Ihrer Website.
- Richten Sie den Googlebot auf eine Weiterleitungskette aus? Googlebot durchläuft jeden Link, auf den er stoßen kann, und gibt sein Bestes, um ihn für die Indizierung zu lesen. Wenn Sie jedoch eine mehrfache, lange, tiefe Weiterleitung einrichten oder wenn die Seite einfach unerreichbar ist, würde Googlebot aufhören zu suchen.
- Den kanonischen Link korrekt implementiert? Ein kanonischer Tag wird im HTML-Header verwendet, um Googlebot mitzuteilen, welche Seite die bevorzugte und kanonische Seite im Falle von doppeltem Inhalt ist. Jede Seite sollte einen kanonischen Tag haben. Zum Beispiel haben Sie eine Seite, die ins Spanische übersetzt ist. Sie werden die spanische URL selbst kanonisieren und Sie möchten die Seite zurück zu Ihrer standardmäßigen englischen Version kanonisieren.
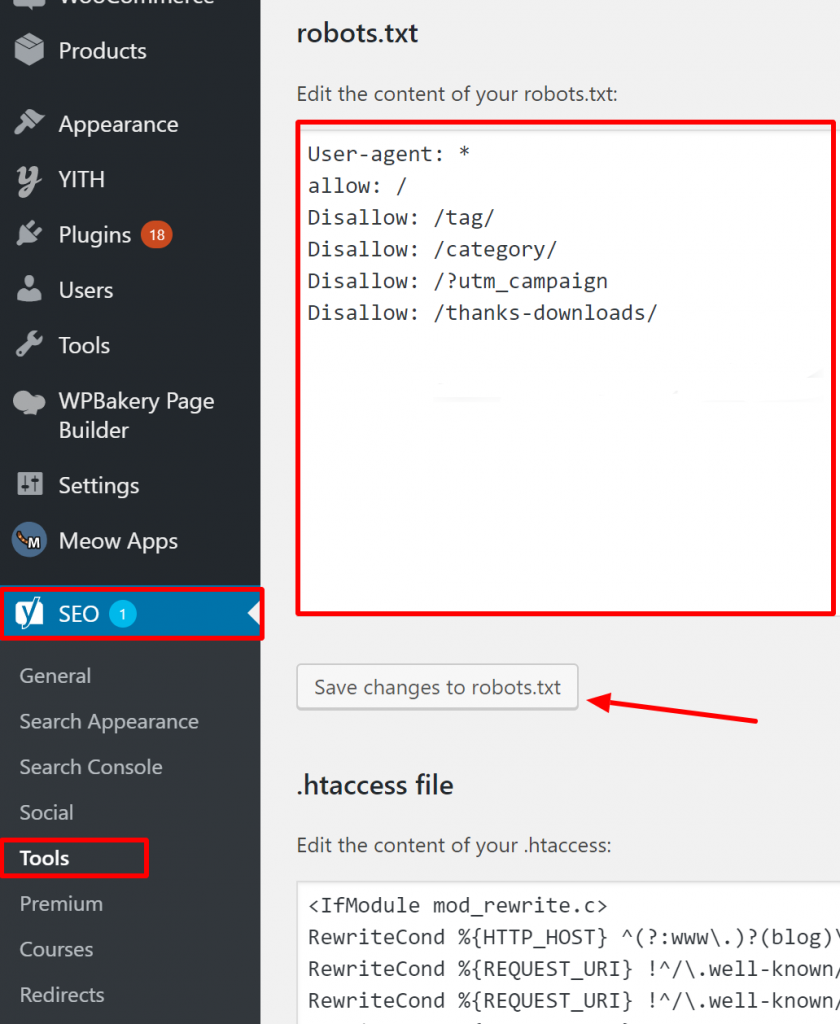
Wie Sie überprüfen, ob Ihre Robots.txt auf WordPress korrekt ist?
Für WordPress, wenn Ihre robots.txt-Datei Teil der Site-Installation ist, verwenden Sie das Yoast Plugin, um sie zu bearbeiten. Wenn die robots.txt-Datei, die Probleme verursacht, auf einer anderen Website ist, die nicht Ihre eigene ist, müssen Sie mit den Website-Betreibern kommunizieren und sie bitten, ihre robots.txt-Datei zu bearbeiten.
Seiten, die nicht indexiert werden sollten
Es gibt mehrere Gründe, warum Seiten, die nicht indiziert werden sollten, indiziert werden. Hier sind einige:
Robots.txt-Direktiven, die "sagen", dass eine Seite nicht indexiert werden soll. Beachten Sie, dass Sie die Seite mit einer 'noindex'-Direktive crawlen lassen müssen, damit die Suchmaschinen-Bots "wissen", dass sie nicht indexiert werden soll.
In Ihrer robots.txt-Datei stellen Sie sicher, dass:
- Die Zeile ‘disallow’ folgt nicht unmittelbar auf die Zeile ‘user-agent’.
- Es gibt nicht mehr als einen ‘user-agent’-Block.
- Unsichtbare Unicode-Zeichen - Sie müssen Ihre robots.txt-Datei durch einen Texteditor laufen lassen, der Kodierungen umwandelt. Dies wird alle Sonderzeichen entfernen.
Seiten sind von anderen Seiten verlinkt. Seiten können indexiert werden, wenn sie von anderen Seiten verlinkt sind, selbst wenn sie in der robots.txt ausgeschlossen sind. In diesem Fall erscheinen jedoch nur die URL und der Ankertext in den Suchmaschinenergebnissen. So werden diese URLs auf der Suchergebnisseite (SERP) angezeigt:
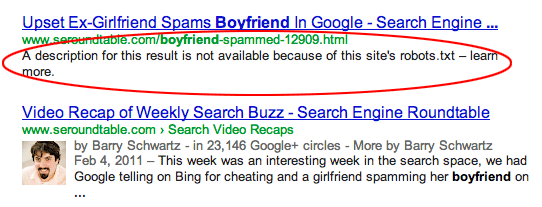 Bildquelle Webmasters StackExchange
Bildquelle Webmasters StackExchange
Ein Weg, das Problem mit der Blockierung durch robots.txt zu lösen, besteht darin, die Datei(en) auf Ihrem Server mit einem Passwort zu schützen.
Alternativ löschen Sie die Seiten aus der robots.txt oder verwenden Sie den folgenden Meta-Tag, um zu blockieren
sie:
<meta name="robots" content="noindex">
Alte URLs
Wenn Sie neuen Inhalt oder eine neue Website erstellt und eine „noindex“-Direktive in robots.txt verwendet haben, um sicherzustellen, dass sie nicht indexiert wird, oder sich kürzlich für GSC angemeldet haben, gibt es zwei Möglichkeiten, das Problem „durch robots.txt blockiert“ zu beheben:
- Gib Google Zeit, um die alten URLs schließlich aus seinem Index zu entfernen
- Leite die alten URLs mit einem 301-Redirect auf die aktuellen um
Im ersten Fall entfernt Google letztendlich URLs aus seinem Index, wenn sie nur 404-Fehler zurückgeben (was bedeutet, dass die Seiten nicht existieren). Es ist nicht ratsam, Plugins zu verwenden, um Ihre 404s umzuleiten. Die Plugins könnten Probleme verursachen, die dazu führen können, dass GSC Ihnen die Warnung „blocked by robots.txt“ sendet.
Virtuelle robots.txt-Dateien
Es besteht die Möglichkeit, eine Benachrichtigung zu erhalten, auch wenn Sie keine robots.txt-Datei haben. Dies liegt daran, dass CMS (Customer Management Systems) basierte Websites, zum Beispiel WordPress, virtuelle robots.txt-Dateien haben. Plug-ins können ebenfalls robots.txt-Dateien enthalten. Diese könnten die Ursache für Probleme auf Ihrer Website sein.
Diese virtuellen robots.txt müssen durch Ihre eigene robots.txt-Datei überschrieben werden. Stellen Sie sicher, dass Ihre robots.txt eine Direktive enthält, die es allen Suchmaschinen-Bots erlaubt, Ihre Website zu durchsuchen. Dies ist der einzige Weg, wie sie feststellen können, welche URLs indiziert werden sollen oder nicht.
Hier ist die Direktive, die es allen Bots erlaubt, Ihre Website zu durchsuchen:
User-agent: *
Disallow: /
Es bedeutet ‚verbiete nichts‘.
Zusammenfassend
Wir haben uns die Warnung ‚Indexed, though blocked by robots.txt‘ angesehen, was sie bedeutet, wie man die betroffenen Seiten oder URLs identifiziert, sowie den Grund hinter der Warnung. Wir haben uns auch angesehen, wie man sie behebt. Beachten Sie, dass die Warnung nicht gleichbedeutend mit einem Fehler auf Ihrer Website ist. Wenn Sie sie jedoch nicht beheben, könnte dies dazu führen, dass Ihre wichtigsten Seiten nicht indiziert werden, was nicht gut für die Benutzererfahrung ist.










